제 블로그의 모든 글은 IMHO로 쓴 것입니다. 잘못된 부분이 있으면 덧글을 통해서 소통을 하면 더 좋은 글로 발전이 될 수 있을 것 같습니다. 그렇지만 소통을 할 때 서로의 감정을 존중하는 선에서 해주셨으면 좋겠습니다. 감사합니다:) — 이 글은 시리즈물 입니다.
- [1편] 트랜잭션 (트랜잭션의 정의, 대상, ACID)
- https://joosjuliet.github.io/transaction/
- (작성중)[2편] DB에서의 트랜잭션(제어어(TCL)[COMMIT, ROLLBACK, SAVEPOINT], mysql에서의 트랜잭션)
- https://joosjuliet.github.io/tcl/
- (작성중)[3편] SPRING에서의 트랜잭션(jpa에서 transaction이란)
-
https://joosjuliet.github.io/jpa_transaction/
-
트랜잭션(transaction)
- 데이터베이스의 상태를 변화시키기 해서 수행하는 작업의 단위를 뜻한다.
ACID
- 트랜잭션의 특성
- Atomicity
- All or nothing
- 다 되거나, 다 안되거나
- Consistency
- 성공적으로 수행된 트랜잭션은 그 transaction속 에 있는 데이터들을 가진 데이터베이스에만 반영된다. 트랜잭션의 수행을 데이터베이스 상태 간의 전이(transition)로 봤을 때, 트랜잭션 수행 전후의 데이터베이스 상태는 각각 일관성이 보장된다.
- 예1)기본 키, 외래 키 제약과 같은 명시적인 무결성 제약 조건들이 명시적 일관성으로 보존된다.
- 예2)자금 이체 예에서 두 계좌 잔고의 합은 이체 전후가 같아야 한다는 사항과 같은 비명시적인 일관성 조건들로 보존된다.
- Isolation
- 트랜잭션이 하나 실행되는 동안 다른 트랜잭션이 실행 되지 못한다.
- Duration
- 한 트랜잭션이 한번 완료되면 이 트랜잭션이 갱신한 것은 그 이후에 시스템에 고장이 발생하더라도 손실되지 않는다. 성공적으로 트랜잭션이 적용되면 영원히 적용된다.
- 예) wal(write a head logging)
- db 쓸 때 로깅해놔서 recovery 할 때 쓰는 것
ACID를 통과하는 법
- Concurrency Control(동시성 제어)
- Logging and Recovery 크게 위 두가지를 만족하면 된다.
Concurrency Control은 Consistency와 Isolation을 실현시켜 가능해졌고, Logging and Recovery는 Atomicity와 Durability를 실현시켜 가능해졌다.
Concurrency Control(동시성 제어)
동시성 제어가 생기는 상황
- 여러 사용자들이 동시에 동일한 테이블을 접근한다
동시성 제어를 하는 법
- idea
- 트랜잭션을 수행하는 각 사용자가 혼자서 데이터베이스를 접근하는 것처럼 생각하도록 해야한다!
- 해결방법(데이터베이스의 일관성을 유지하는 법)
- serial schedule
- 여러 트랜잭션들의 집합을 한번에 한 트랜잭션씩 차례대로 수행하는 스케줄.
- 즉 다중처리가 아니라 한번에 하나씩만 하고 중간에 다른 작업이 끼지 않는다.
- 예) 은행의 ATM 머신의 경우, 모든 은행의 고객들이 한번에 한명씩 밖에 현금인출을 할 수 없다.
- serial schedule
- serializable
- 사실 db system이 동시에 트렌젝션을 수행한다면 serial 할 필요가 없다.
- 근데 만약 동시 수행의 제어권이 전적으로 os에게 있따면 여러가지 가능한 스케줄이 있어서 데이터베이스 시스템을 모순상태로 만들 수 있다.
- 그렇기 때문에 일관된 상태로 유지시켜야 하는데 그것의 역할은 db에 있다.
- 즉 여러 트랜잭션을 동시에 수행했는데도 serial schedule과 결과가 동일하다면 그건 serializable 스케줄 이다.
동시성 제어가 제대로 이루어지지 않으면 생기는 일
- lost update
- dirty read
- unrepeatable read
Lost Update
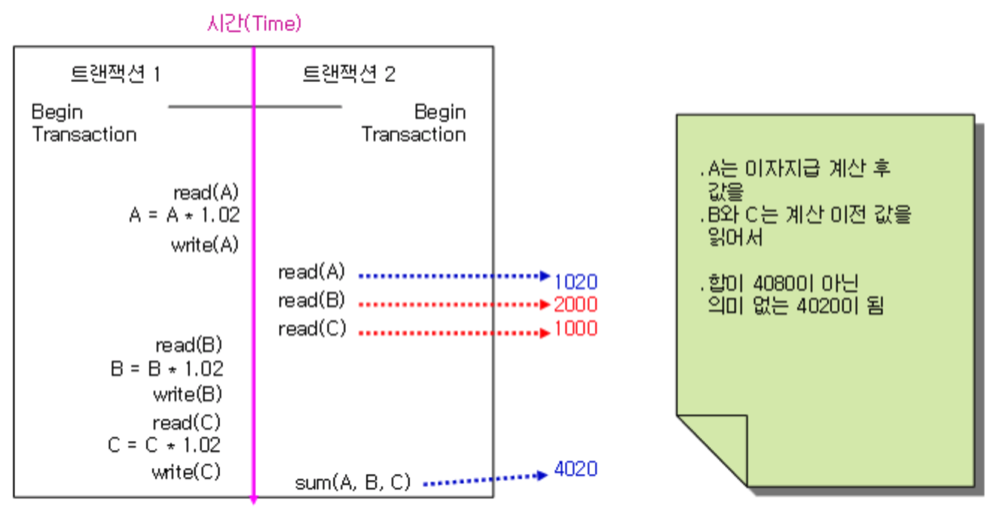
- t2에서 t1의 결과가 디스크에 쓰여지기 전에 t2에서 읽어버려서 t1내용을 덮어썼다.
Dirty Read
- t1은 a,b,c 각각에 1.02를 곱한 후 저장하고 싶었다.
-
t2는 a,b,c를 더한다.
- t1은 각 data에 1.02를 곱하려 하고 t2는 세가지 값을 더하려고 했다.
- 근데 t1에서 data 3개를 다 쓰기도 전에 t2가 값을 읽어버렸다.
- 세개가 이제 다 적용된 결과가 나와야하는데 그게 아닌 것이다.
Unrepeatable Read
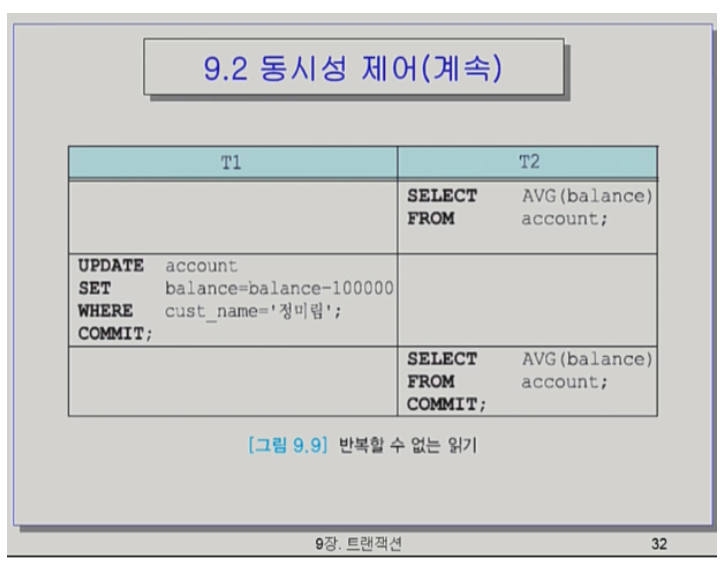
- t2입장에서는 isolation이 깨지고 Consistency가 보장이 안된다.
- transaction 속에서는 값이 같아야 하는데 중간에 값이 바뀐 것이다.
- 같은 결과를 반복적으로 읽을 수가 없다.
Locking으로 해결
- DB 내의 모든 데이터 항목마다 Lock이 존재함
- 트랜잭션이 수행을 시작해 데이터 항목을 접근할 때마다 요청한 lock에 대한 정보는 lock table 등에 유지된다
Lock의 종류
Shared lock (공유 잠금)
- S-lock
- 리소스를 다른 사용자가 동시에 읽을 수 있게 하되 변경은 불가하게 하는 것
- 어떤 자원에 shared lock이 동시에 여러개 적용될 수 있다.
- 어떤 자원에 shared lock이 하나라도 걸려있으면 exclusive lock을 걸 수 없다.
Exclusive lock (배타적 잠금)
- X-lock
- 어떤 트랜잭션에서 데이터를 insert/update를 할 때 해당 트랜잭션이 완료될 때까지 해당 테이블 혹은 레코드(row)를 다른 트랜잭션에서 읽거나 쓰지 못하게 lock을 걸고 트랜잭션을 진행시키는 것이다.
- exclusive lock에 걸리면 shared lock을 걸 수 없다.
- exclusive lock에 걸린 테이블, 레코드등의 자원에 대해 다른 트랜잭션이 exclusive lock을 걸 수 없다.
Lock은 잠금 비용과 동시성비용을 고려해야한다.
- 기본적으로 db도 자원이라는 것을 머리속에 가지고 있어야 한다.
- 만약 lock을 걸어야할 row가 많다면, 그럴바에 테이블 전체에 lock을 걸어버리는 편이 한번에 처리하니까 잠금 비용에 낮아져 효율적이다.
- 하지만 lock의 범위가 넓어질수록 동시에 접근할 수 없는 자원이 많아지므로 동시성 비용이 높아져 효율이 떨어진다.
Locking만으로 동시성 문제 해결?
- 단순히 locking을 사용한다고 해서 동시성 문제가 완전하게 해결되지는 않는다.
- 언제 lock을 주고 unlock을 주느냐에 따라 다르다.
해결책
- 2Phase Locking(2PL) Protocol
- 다중단위 lock
2Phase Locking(2PL) Protocol
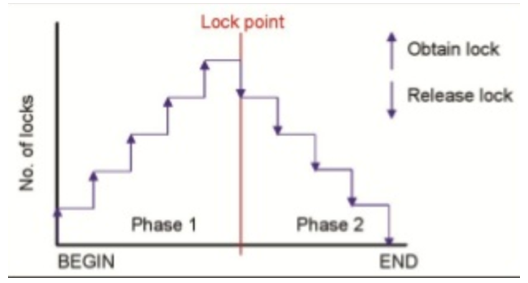
- 2 phase locking protocol 에서는 locking과 unlock하는 것이 2 phase로 이루어진다.
- 2PL Protocol을 준수한다면, 모든 트랜잭션은 직렬성을 보장받음.
- Phase 1: lock 확장 단계, 이 단계에서는 트랜잭션이 locking을 할 수는 있지만 unlock은 할 수 없다.
- Phase 2: lock 수축 단계, 이 단계에서는 unlock만 할 수 있다. lock을 서서히 하나씩 해제할 수도 있고, 한꺼번에 걸어놓았던 모든 lock을 해제할 수도 있다.
- 필요한 모든 lock이 걸린 시점을 lock point라고 한다.
- deadlock이 발생할 수 있다. 데드락(Deadlock) 두 개 이상의 트랜잭션이 각각 자신의 데이터에 대하여 락을 획득하고 상대방 데이터에 대하여 락을 요청하면 무한 대기 상태에 빠질 수 있는 현상
다중 단위 lock (multiple granularity)
- lock은 충돌을 검사하고 lock 정보를 기록해야 하기 때문에 자주 걸면 overhead가 발생한다.
- 따라서 lock의 단위, 범위를 다양하게 할 수 있다.
- 데이터베이스, Relation, 디스크블록(페이지), 레코드(튜플)의 단위로 lock을 걸 수 있다. (뒤로 갈수록 overhead가 많이 발생하고, 동시성의 정도가 증가한다.)
- 단위가 작아질 수록 fine grained lock이 된다.
- lock을 정교하게 거는 것이 fine grained lock이다.
- 상대적으로 정교하지 않게 하는 것은 coarse grained lock이다.
Phantom Read
lock을 tuple단위로 걸었다고 하자. Transaction이 Range를 조건절로 걸었고, 새로운 데이터도 Range 범위에 해당되는 경우 T1이 끝날때까지 HONG GILDONG에 lock이 걸려있다고 하더라도, 추후에 생길 Bob에 대한 튜플과는 관련이 없으므로 Bob이 그대로 삽입된다. T1이 다시 읽기를 하게 되면, Bob이라는 유령(Phantom)이 삽입되어 있다. next key lock이 해결방법이다.(다음에 들어올 tuple에도 lock을 건다.)

- lock을 tuple단위로 걸었다고 하자.
- Transaction이 Range를 조건절로 걸었고, 새로운 데이터도 Range 범위에 해당되는 경우
- T1이 끝날때까지 HONG GILDONG에 lock이 걸려있다고 하더라도, 추후에 생길 Bob에 대한 튜플과는 관련이 없으므로 Bob이 그대로 삽입된다.
- T1이 다시 읽기를 하게 되면, Bob이라는 유령(Phantom)이 삽입되어 있다.
- next key lock이 해결방법이다.(다음에 들어올 tuple에도 lock을 건다.)
- 근데 이건 구현체 마다 다르다.
Logging and Recovery
Recovery
- 트랜잭션을 수행하는 도중에 시스템이 다운된다면?
- 디스크의 헤드가 고장나면?
- 트랜잭션이 종료된 직후에 시스템이 다운되면? 디스크에 기록되지 않으면? 이런 경우에도 트랜잭션의 원자성과 지속성을 보장해야 한다.
- 그래서 Logging을 해 Recovery를 할 수 있게 하는 것이다.
회복 관련 용어 정리
- Main memory의 buffer는 디스크로부터 데이터를 읽거나 디스크에 데이터를 기록하는 비용을 최소화 하기 위한 완충 역할을 수행한다.
- REDO: 고장이 발생한 시점 전에 트랜잭션이 이미 commit된 상태라면 REDO
- UNDO: 트랜잭션이 commit을 완료하지 못했다면 원자성을 보장하기 위해 UNDO
- backup: DB를 주기적으로 자기 테이프에 복사
- logging: 현재 수행 중인 트랜잭션의 상태와 DB 갱신 사항을 기록
- check point: 시스템이 붕괴된 후 재기동되었을 때 특정 포인트까지만 복구함으로서 REDO하거나 UNDO해야하는 트랜잭션들의 수를 줄여준다.(일반적으로 10~20분마다 한번씩 수행)
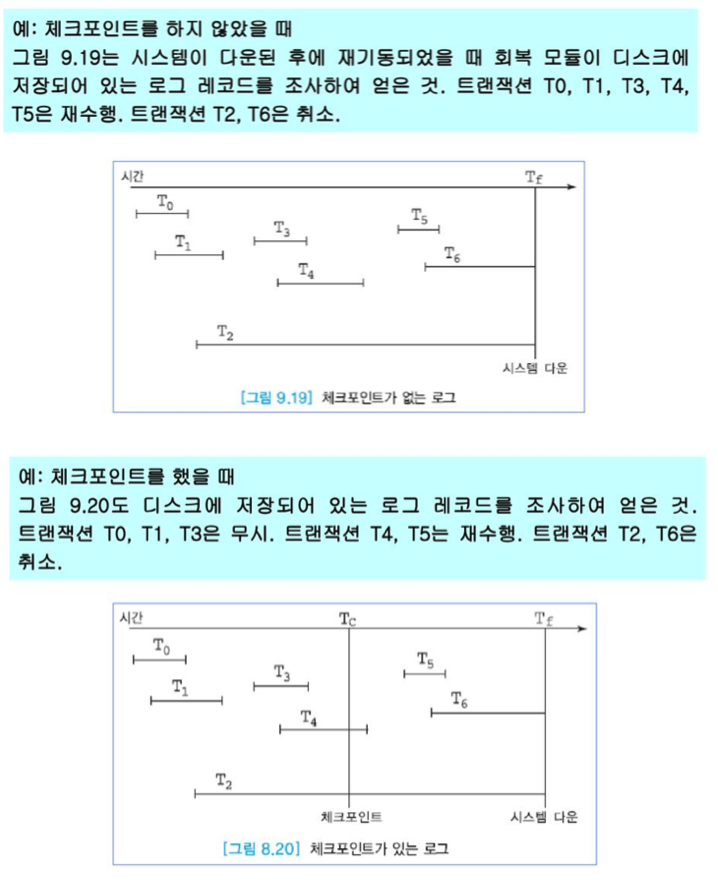
로그를 사용한 즉시 갱신
- 트랜잭션 수행 중에 갱신 결과를 DB에 즉시 반영하고 Log에 기록한다.
- Log에는 갱신되는 항목의 이전 값과 새로운 값 모두를 기록한다.
- 트랜잭션이 완료가 된 상태면 Redo, 완료가 되지 않은 상태면 Undo를 수행한다.
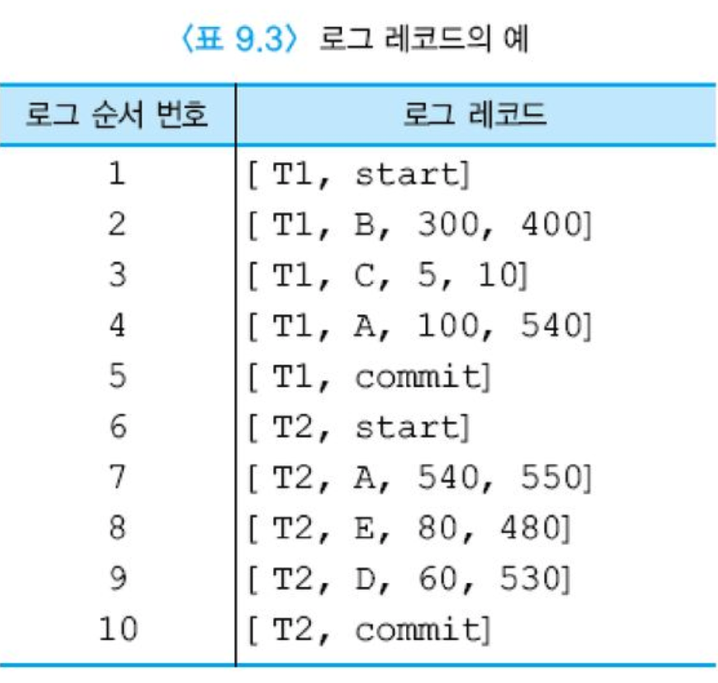
WAL(Write-Ahead-Logging)
- 당연히 로그 내용이 있어야 데이터 베이스 내용을 복구를 해야한다.
- 그래서 로그를 먼저 쓰고 데이터베이스에 쓰는 행위를 WAL이라한다.
- 로그-먼저-쓰기: Write-Ahead-Logging
Isolation Level(고립 수준)
- READ UNCOMMITED
- 가장 낮은 고립 수준. Commit 되지도 않은 데이터를 읽어들인다. 즉, S-lock을 걸지 않고, X-lock만 건다. 따라서 Dirty read가 일어날 수 있다.
- READ COMMITED
- Commit된 데이터를 읽는다, 하지만 그렇다고 하더라도 read를 반복적으로 하는 트랜잭션 도중에 데이터의 내용이 commit 된다면 일관성이 깨질 수 있으므로 Unrepeatable read 문제는 여전히 남아있다.
- REPEATABLE READ
- 검색되는 데이터에 대해 S-lock을 걸고, 트랜잭션이 끝날때까지 보유한다. 검색되는 데이터가 트랜잭션 중간에 추가되고, 다시 한번 read 한다면 phantom read가 일어날 수 있다.
- SERIALIZABLE
- Phantom read까지 다 없앤 고립수준. 내부의 구현 방식은 DB마다 다름. 예를 들면 next key lock을 사용해 해결.
고립수준이 높을 수록 얻는 문제
한번에 많은 것을 고립시키다보니 그걸 기다리다보니 속도가 느려질 수 밖에 없다.
참고: https://m.blog.naver.com/PostView.nhn?blogId=adidas_83&logNo=130152784549&proxyReferer=https%3A%2F%2Fwww.google.com%2F
https://d2.naver.com/helloworld/407507
https://m.blog.naver.com/PostView.nhn?blogId=kyung4502&logNo=221028580665&proxyReferer=https%3A%2F%2Fwww.google.com%2F
https://jeong-pro.tistory.com/94