[db index 2편] index structure의 종류 (cluster index, non-cluster index, Hash Index, B Tree, B+ Tree, Fractal-Tree, Adaptive Hash Index)
09 Jan 2019
Reading time ~4 minutes
이 컨텐츠는 시리즈물입니다.
[db index 1편] index 란?: https://joosjuliet.github.io/index/
[db index 2편] index structure란?:
https://joosjuliet.github.io/index_structure/
[db index 3편] index structure의 종류와 선정 지침
https://joosjuliet.github.io/index_guidline/
Index Architecture
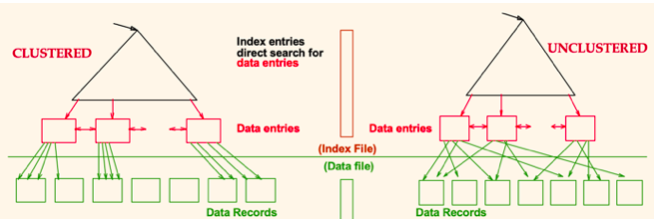
실제 데이터 엔트리와 데이터 레코드의 순서가 같으면 Clustered Index, 아니면 Non-Clustered Index
Clustered Index
- 실제 데이터 엔트리와 데이터 레코드의 순서가 같다.
- clustered index가 걸린 컬럼은 자동으로 그 컬럼을 기준으로 정렬한다.(테이블 당 하나의 컬럼만 가능)
- 두개의 컬럼에 하면 정렬이 불가능함으로
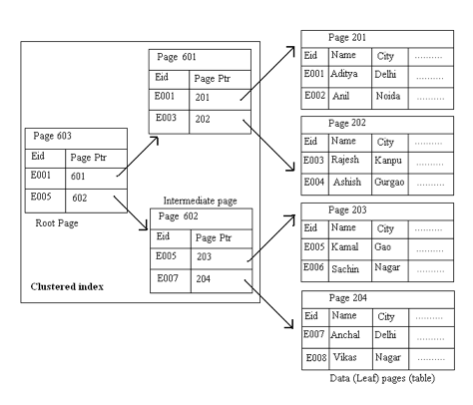
- primary key를 걸면 default로 clustered index가 걸린다.
- 범위의 시작값을 찾고 연속된 디스크 블록을 읽으면 되니, Range Query에 좋다.
- hard disk에는 세가지 time이 있다.
- 1.seek time (어떤 track을 찾는냐)
- 2.rotation latency(원판 도는 time)
- 3.transmission time(data 읽어서 전송하는 시간)
- disk가 원판으로 생겨서 돌아가면서 데이터를 읽는다.
-> 원판에는 track이 있고 그 track들에 data가 들어가 있다.
-> 가장 오래걸리는 시간은 seek time이다.
-> 그러므로 data 연속되어 있으면 1,2번의 시간이 줄어서 효율적이 된다.
그래서 clustered index에 range query가 좋다!
- hard disk에는 세가지 time이 있다.
Non-Clustered Index
- 실제 데이터 엔트리와 데이터 레코드의 순서가 같지 않다.
- 특정 index에 맞춰서 ordering할 필요가 없으니 테이블 당 여러개의 컬럼에 index 거는 게 가능
- secondary index에 주로 non-clustered index를 적용
- Range Query를 하면 그 구간의 record들을 읽기 위해 각 record마다 매번 디스크 블록에 접근한다. -> 접근 횟수가 많아 db 성능에 critical
- 따라서 해당하는 데이터 엔트리를 찾는 속도는 (index가 없는 것 보다) 빠르지만, 레코드를 읽는 속도는 (clustered index보다 상대적으로)느리다.
- mysql의 InnoDB의 경우 unique를 걸면 자동으로 non-clustered index가 걸린다.
- unique는 중복이 제거된 것이기 때문에 indexing이 되면 효율이 높아지기 때문에 optimizer가 자동으로 해준다.
- 중복이 없을 때 index를 걸면 효율이 좋다.
- equality 연산은 index에 좋다.(찾는 시간이 단축되니까)
- InnoDB에서는 Foreign key를 써도 자동으로 non-cluster Index를 생성한다.
- join연산을 where문으로 했을 때, join 연산은 primary key와 foreign key의 equality연산을 하기 때문에 그게 성능이 좋아서 한다.
- non-unique한 column도 index를 걸 수 있다
index를 위한 data structure
- Hash Index
- postgres
- B Tree
- MongoDB
- B+ Tree
- CUBRID, InnoDB, postgres
- Fractal-Tree
- TokuDB
TMI1: postgres는 index types이 B-tree, Hash, GiST and GIN가 있다 TMI2: Mysql 5.5부터 InnoDB가 기본 스토리지 엔진, 그 전에는 MyISAM 사용
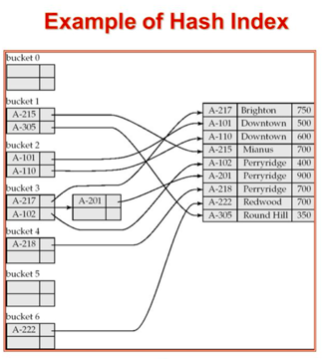
Hash Index
- single level index
- hash table을 생각하면 똑같다.
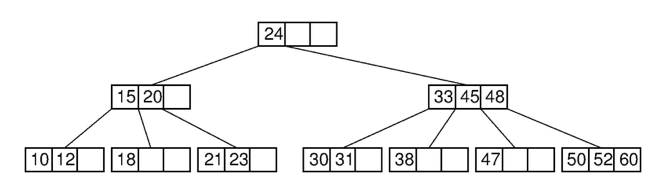
B Tree
-
https://www.cs.usfca.edu/~galles/visualization/BTree.html(b 트리 생성기)
- Binary Tree가 아니라 Balanced Tree이다.
-
이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조이다.
- 모든 leaf node는 모두 같은 level에 있다.
- 따라서 인덱스 탐색 시 중위순회(inorder)를 해야한다
- 노드 내의 값은 오름차순을 유지한다.
- 입력 자료는 중복이 될 수 없다. (위에 b트리 생성기에서는 되는데 원래는 안된다.)
- 하나의 노드 크기가 block 단위(page)
- 모든 노드가 data entry(실제 레코드를 가리키고 있다.)
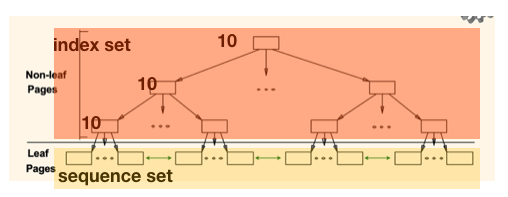
B+ Tree
-
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html(b+ 트리 생성기)
- B tree와 대부분 특징들이 같다 .
- 다른 점은 leaf node들이 서로 list로 연결되어 있고, leaf 노드들만 data entry라는 점이다.
- 예를 들어서 10이 있으면 자식노드들이 모두 10을 가지고 있다.(자식들이 상위것 뿐만 아니라 상위의 상위것 까지 index를 다 가지고 있다.)
- 그럼으로 공간을 많이 먹는다.
- 대신 데이터를 탐색할 때 무적권 logN이 걸린다.
-
그리고 시작포인트만 읽고 쭉 필요한 데이터를 읽으면 됨으로 range qeury에 유용하다.
- 관계 데이터베이스들도 테이블 인덱스를 위해 B+트리 타입을 가끔 사용한다. TMI 파일시스템들은 모두 블록 인덱싱을 위해 B+트리 타입을 사용한다.
B Tree vs B+ Tree
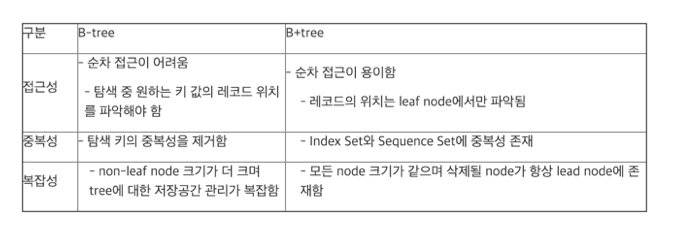
B-Tree 계열의 단점
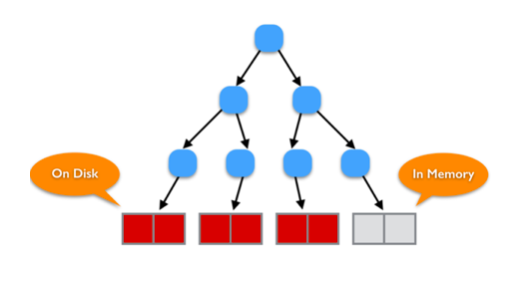
대용량 데이터가 되면 메모리에 다 못올라감 -> Disk I/O 발생! -> Fractal-Tree의 등-장
Fractal-Tree
- “Big I/O”에 촛점을 맞춘 자료 구조로, 잦은 Disk I/O를 줄이고, 한번에 다량의 데이터를 하단 노드로 전달함에 따라 데이터가 많은 상황에서도 효과적으로 처리할 수 있는 방안을 제시
장점
- B Tree의 장점을 그대로 가져오고, 대용량 데이터 환경에서 효율적이다.
- B Tree 인덱스에서 인덱스 키를 검색하거나 변경하는 과정 중에 발생하는 가장 큰 문제는 디스크에서 랜덤으로 값을 찾는 것이었다.
- 그러므로 I/O를 상대적으로 많이 해야한다.
- 우리의 Fractal-Tree는 Sequantial I/O를 가능하게 해준다!
- 인덱스 단편화(Fragmentation)를 최적화 할 필요가 없다.
단점
- transaction은 ACID를 잘 보장해야 하는데 동시성(Concurrency)의 성능이 떨어지기 때문에, 멀티 스레드 환경에서는 성능이 낮고, 따라서 OLTP(transaction) 환경에서는 아직 적용하기에 무리가 있다.
- OLAP(분석), DW(Data Warehouse)에서는 적합함 OLAP, DW, OLTP 용어참고링크!
Fractal-Tree의 동작원리
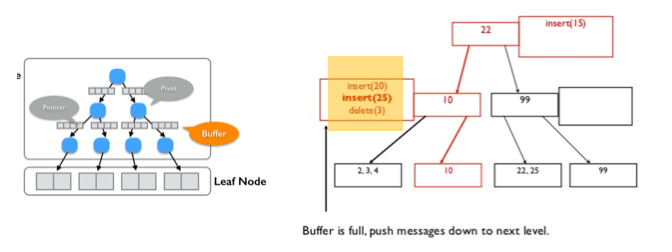
- 모든 내부 노드에 message buffer가 있음.
- 버퍼는 disk i/o의 부담을 줄이기 위해서 하는 것이다.
- 한번에 실행하면 sequential 하게 하니까 더 좋다.
- 버퍼가 가득 차면 더 이상 공간이 없게 되는데, 이 순간 데이터를 자식 노드로 내린다. (내릴 때 동시에 하다보니 데이터 손실 및 많은 것이 부담이 된다.) 이 단계에서 Disk I/O가 발생하는 단계이다.
- B-Tree에서 데이터 유입시 매번 자식 노드로 데이터를 보내며 발생하던 잦은 Disk I/O 수가 Fractal Tree에서는 각 노드에 존재하는 버퍼 공간으로 인해 극적으로 감소한다.
InnoDB의 급격한 성능저하와 그 이유
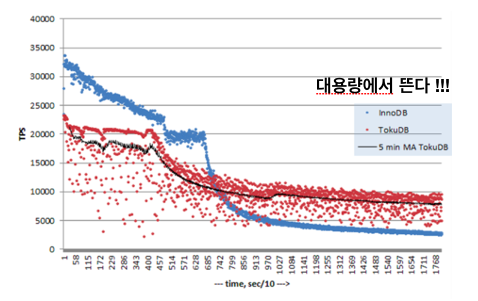
[참고] TPS는 transaction per second, Oracle에서 한 트랜잭션을 commit, rollback의 수를 의미한다면 초당 commit, rollback이 일어나는 횟수이고, Load Runner과 같은 툴에서는 초당 툴을 통해 정의한 한번의 행위(특정 페이지 방문)을 의미한다고 할 수 있다.
- TPS가 일정 수준을 넘어서면 급격한 성능 저하가 발생하는데, Fractal-Tree는 이런 급격한 성능 저하 현상이 없다.
- Fractal-Tree의 평균적인 처리 능력은 이론적으로 B-Tree보다 400배 가량 빠르며, 실제로도 TokuDB의 키 추가 및 삭제 작업은 InnoDB보다 100배 가량 빠른 처리속도를 보여줍니다.
- 이 그래프는 single thread 환경에서 테스트 한 것이다.
- 멀티 스레드 환경에서는 달라질 수 있다.
Adaptive Hash Index
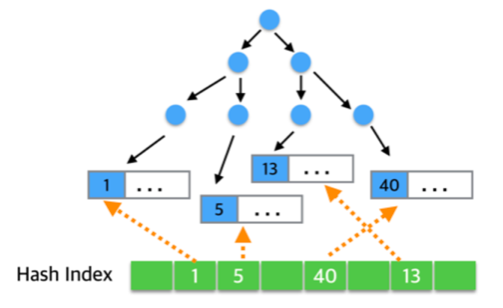
- InnoDB에서 지원함.
- 자주 사용되는 데이터 값을 내부적으로 판단하여 상황에 맞게 해쉬 값을 설정한다.
- 캐싱을 하는 것과 같다. 참고: http://tech.kakao.com/2016/04/07/innodb-adaptive-hash-index/
참고:
InnoDB는 B+tree를 사용한다: https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
B-tree 관련: https://medium.com/@mena.meseha/what-is-the-difference-between-mysql-innodb-b-tree-index-and-hash-index-ed8f2ce66d69
DB테이블에 전부 인덱스를 걸면?:
https://hashcode.co.kr/questions/1551/%EC%99%9C-db-%ED%85%8C%EC%9D%B4%EB%B8%94%EC%9D%98-%EB%AA%A8%EB%93%A0-%EC%BB%AC%EB%9F%BC%EC%97%90-%EC%9D%B8%EB%8D%B1%EC%8A%A4%EB%A5%BC-%EA%B1%B8%EB%A9%B4-%EC%95%88%EB%90%98%EB%82%98%EC%9A%94
Index관련 동영상 강의: https://www.youtube.com/watch?v=de0Ky5IhW0E
B Tree vs B+ Tree 출처: http://www.jidum.com/jidums/view.do?jidumId=157
Fractal Tree
: https://12bme.tistory.com/143?category=682920
- http://gywn.net/2014/05/fractal-index-in-tokudb/
TPS 설명: https://aozjffl.tistory.com/375 [자수성가한 부자]