[db index 1편] index 란? (single level index, dense index, sparse index, composite index, multilevel index )
07 Jan 2019
Reading time ~2 minutes
이 컨텐츠는 시리즈물입니다.
[db index 1편] index 란?: https://joosjuliet.github.io/index/
[db index 2편] index structure란?:
https://joosjuliet.github.io/index_structure/
[db index 3편] index structure의 종류와 선정 지침
https://joosjuliet.github.io/index_guidline/
Index란?
records의 특정 data를 기준으로 빠르게 검색을 할 수 있게 records를 구조화 하는 것
- 원하는 데이터를 빠르게 찾을 수 있게 색인을 하는 것
- 실제 data(record)는 정렬이 되어 있을 수도 있고, 안되있을 수도 있다.
-
구성 : 탐색 키(rid) + 실제 레코드를 가리키는 포인터 (Data record with key value k)
- 장점
- 원하는 data(record)를 쉽게 찾을 수 있다.
- 단점
- index 를 위한 공간이 필요하다.
- 새로운 data를 추가, 삭제, 변경 시 이에 상응되는 인덱스 추가, 삭제, 변경이 필요할 수 있다.(거의 대부분 필요하다.)
Types of Indexes
- single level index
- composite index
- multilevel index
Single Level Index
- 정렬되어 있기 때문에 이진 탐색에 좋다.
- where key = 1003 인덱스가 걸린 컬럼의 where문 =(equality)(equality search)이 빠르다
- 메모리에 index table의 데이터 크기가 본 table의 것보다 작으므로 테이블을 탐색할 수 있는 양이 더 늘어나, 더 많은 양이 한번에 할 수 있기 때문에 탐색시간이 단축된다.
- 인덱스를 primary key에 걸면 Primary Index(기본 인덱스), 다른 컬럼에 걸면 Secondary Index(보조 인덱스) 이다.
Ordered Indexing is of two types
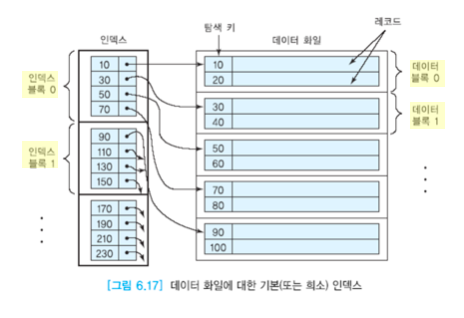
- Dense Index
- Sparse Index
Dense Index
한 index에 원하는 record가 바로 매칭된다.
- 밀집 인덱스
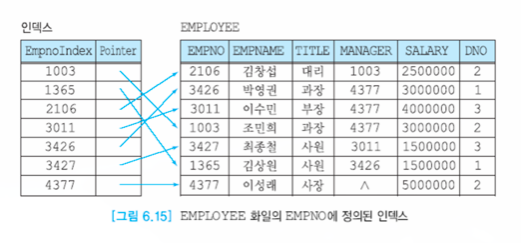
Sparse Index
index에 data block이 매칭된다.
- 느슨한 인덱스
- block 속에서 진짜 자기가 원하는 값을 찾아야 한다.
- data를 fragnation이 일어나지 않고, 효율성을 높이기 위해서 블록 단위로 놓는 것이다.
Composite Index
여러개의 column에 indexing
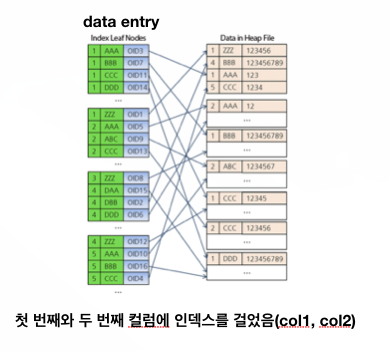
- single index가 한 cloumn에 indexing을 하는 것과 다르게 여러개의 column에 indexing을 한다.
- 예제
- 선린인터넷고 웹운영과 relation에 총 30명의 사람(2명이 female, 28명이 male)이 있고, 각자 물건들을 가지고 있음.(2명은 펜, 또 다른 3명은 지우개)
- 이런 류의 query문이 많다고 가정하자
where gender = ‘male’ and having-item = ‘pen’; where gender = ‘female’ and having-item = ‘eraser’; - 이런 경우엔 (gender, having-item) 두 컬럼에 composite index를 걸 수 있음
- 인덱스에 걸려있는 것 중에서 먼저 걸린 index를 먼저 찾는다.(예제로 따지면 gender가 앞에 있으니 gender를 찾고 having-item을 찾는다.₩)
- 28명의 남자들 중에서 pen을 든 사람을찾는 것보다, pen을 든 사람들 중에서 남자를 찾는 것이 더 빠름! -> 따라서 (having-item, gender)의 순서로 composite Index를 걸자!
- 즉 빈도수가 적은 인덱스를 먼저 거는게 더 좋다.
-
결합 인덱스를 만들어보자
CREATE TABLE table_name ( c1 data_type PRIMARY KEY, c2 data_type, c3 data_type, c4 data_type, INDEX index_name(c2, c3, c4) );- c2를 먼저 되고, 그다음에 c3 순서대로 정렬, c4 순서대로 정렬 그다음에 data 가리키는 pointer
Multi Level Index
인덱스 레벨이 많으면 multi level index
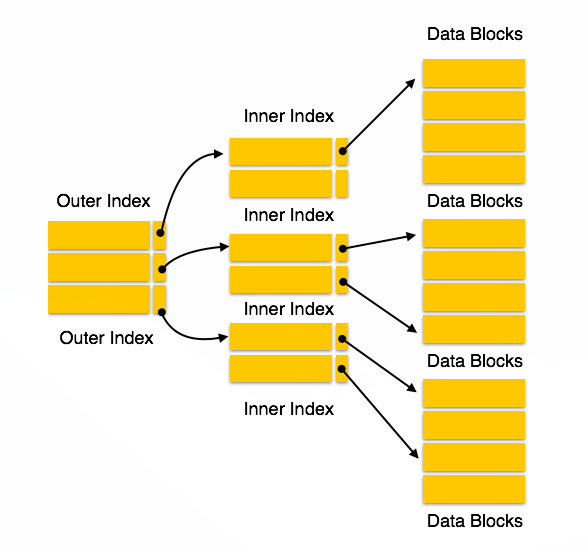
- 인덱스를 위한 인덱스를 위한 인덱스를 위한… 인덱스!
- 데이터가 커지면 index 크기 역시 커집니다.
- 그러므로 single level index를 사용할 수가 없어 multilevel index를 사용합니다.
- inner index(원래 인덱스)를 작은 색인으로 분할하여 outer index를 작게 만든다.
- 그로 인한 단점으로 I/O가 자주 일어난다.
- 실제 데이터베이스 파일과 함께 디스크에 저장됩니다.
참고 :
https://en.wikipedia.org/wiki/Database_index
https://www.tutorialspoint.com/dbms/dbms_indexing.htm
http://web.cs.ucdavis.edu/~green/courses/ecs165a-w11/7-indexes.pdf
http://mee2ro.tistory.com/2 [Meero]
데이터베이스 배움터
친구 데이터베이스 수업 자료
결합 인덱스 : http://dinggur.tistory.com/228
http://mee2ro.tistory.com/2