https를 알기 앞서 http를 먼저 설명 고!
HTTP(HyperText Transfer Protocol)란?
HTTP는 클라이언트와 서버 사이에 이루어지는 요청/응답(request/response) 프로토콜이다.
HTTP와 TCP/IP
TCP/IP는 마치 한계층에 있을 것 같지만 다른 계층에 있다.
IP
일단 IP는 네트워크에서는 2계층 인터넷 계층(Internet Layer), OSI 7계층의 네트워크 계층에 해당한다. 그 계층에서 주로 하는 일은 통신 노드 간의 IP패킷을 전송하는 기능과 라우팅을 하는 것이다. (대표 프로토콜 중 하나가 IP)
TCP
TCP는 3계층 전송 계층(Transport Layer), OSI 7계층의 전송 계층에 해당된다. 그 계층에서는 통신 노드 간의 연결을 제어하고, 오류없이 데이터를 전달 및 수신한다. (대표 프로토콜은 TCP, UDP)
HTTP는 애플리케이션 계층에서 일어나는 프로토콜이며 네트워크의 세부적인 사항은 대중성, 신뢰성 두 가지를 담당하는 TCP/IP가 있는 layer에서 일어난다.
그로인해 아래와 같은 장점을 갖게 된다.
- 오류 없는 데이터 전송
- 순서에 맞는 전달(보낸 순서대로 전달)
- 조각나지 않는 데이터 스트림
Connectless & Stateless
HTTP는 Connectless 방식으로 작동한다. 서버에 연결하고, 요청해서 응답을 받으면 연결을 끊어버린다. 기본적으로는 자원 하나에 대해서 하나의 연결을 만든다. 이런 작동방식은 각각 아래의 장점과 단점을 가진다.
- 장점 : 불특정 다수를 대상으로 하는 서비스에 적합한 방식이다. 수십만명이 웹 서비스를 사용하더라도 접속유지는 최소한으로 할 수 있기 때문에, 더 많은 유저의 요청을 처리할 수 있다.
- 단점 : 연결을 끊어버리기 때문에, 클라이언트의 이전 상태를 알 수가 없다. 이러한 HTTP의 특징을 stateless라고 하는데, Connectless로 부터 파생되는 특징이라고 할 수 있다. 클라이언트의 이전 상태 정보를 알 수 없게 되면, 웹 서비스를 하는데 당장에 문제가 생긴다. 예컨데, 클라이언트가 과거에 로그인을 성공하더라도 로그 정보를 유지할 수가 없다. HTTP는 cookie를 이용해서 이 문제를 해결하고 있다.
URI
https://joosjuliet.github.io/web_technical_interview/
의 2번 URI vs URL vs URN 을 참고해주세요 :)
요청 헤더에는 가져올 리소스 또는 리소스를 요청하는 클라이언트에 대한 자세한 정보가 포함되어 있습니다. 응답 헤더에는 응답 위치 또는 응답을 제공하는 서버와 같은 응답에 대한 추가 정보가 있습니다.
요청 데이터 포멧
웹 브라우저는 웹 서버에 데이터를 요청하는 “클라이언트 프로그램” 이다. 요청은 서버가 인식할 수 있는 약속된 형식(HTTP 형식)을 따라야 한다. 요청 데이터는 “HEADER”와 “BODY”로 구성된다.
헤더에는 요청과 요청 데이터에 대한 메타정보들이 들어있다.
GET /cgi-bin/http_trace.pl HTTP/1.1\r\n
ACCEPT_ENCODING: gzip,deflate,sdch\r\n
CONNECTION: keep-alive\r\n
ACCEPT: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n
ACCEPT_CHARSET: windows-949,utf-8;q=0.7,*;q=0.3\r\n
USER_AGENT: Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24\r\n
ACCEPT_LANGUAGE: ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4\rn
HOST: www.joinc.co.kr\r\n
\r\n
HTTP 헤더는 라인피드와 캐리지 리턴(/r/n)을 함께 사용한다. HTTP 헤더를 파싱할 때 주의해야 한다.
필수 요소로 요청의 제일 처음에 와야 한다 3개의 필드로 이뤄져 있다.
- 요청 메서드 : GET, PUT, POST, PUSH, OPTIONS 등의 요청 방식이 온다.
- 요청 URI : 요청하는 자원의 위치를 명시한다.
- HTTP 프로토콜 버전 : 웹 브라우저가 사용하는 프로토콜 버전이다.
응답 헤더 포멧
응답 헤더포멧이다.
HTTP/1.1 200 OK
Date: Fri, 08 Jul 2011 00:59:41 GMT
Server: Apache/2.2.4 (Unix) PHP/5.2.0
X-Powered-By: PHP/5.2.0
Expires: Mon, 26 Jul 1997 05:00:00 GMT
Last-Modified: Fri, 08 Jul 2011 00:59:41 GMT
Cache-Control: no-store, no-cache, must-revalidate
Content-Length: 102
Keep-Alive: timeout=15, max=100
Connection: Keep-Alive
Content-Type: text/html
-
- 프로토콜과 응답코드 : 반드시 첫줄에 와야 한다. 3개의 필드로 구성돼 있다.
- HTTP/1.1 : 응답 프로토콜과 버전
- 200 : 응답 코드
- OK : 응답 메시지. Not Found, Internal Server Error 등의 메시지다.
- 프로토콜과 응답코드 : 반드시 첫줄에 와야 한다. 3개의 필드로 구성돼 있다.
-
- 날짜
-
- 서버 프로그램및 스크립트 정보.
-
- 응답헤더에는 다양한 정보를 추가할 수가 있다. 어떤 정보를 추가할지는 개발자 마음이다.
-
- 컨텐츠의 마지막 수정일
-
- 캐쉬 제어 방식.
-
- 컨텐츠 길이.
-
- Keep Alive기능 설정이다.
-
- Content-Type
- 응답에 실어 보내는 컨텐츠가 어떤 형태인지를 알려준다. 웹 애플리케이션들은 Content-Type에 따라서 Body의 데이터를 어떻게 읽을지를 결정한다. 따라서 전송 데이터에 맞는 content-type를 명시해야 한다.
- Content-Type
Keep Alive
keep alive는 클라이언트측에 연결을 유지하라는 신호를 보내기 위해서 사용한다. 그러면 클라이언트는 최대 timeout에 지정된 시간동안 연결을 유지한다. 이 시간동안 클라이언트는 이미 맺어진 연결로 요청을 계속 보낼 수 있다. 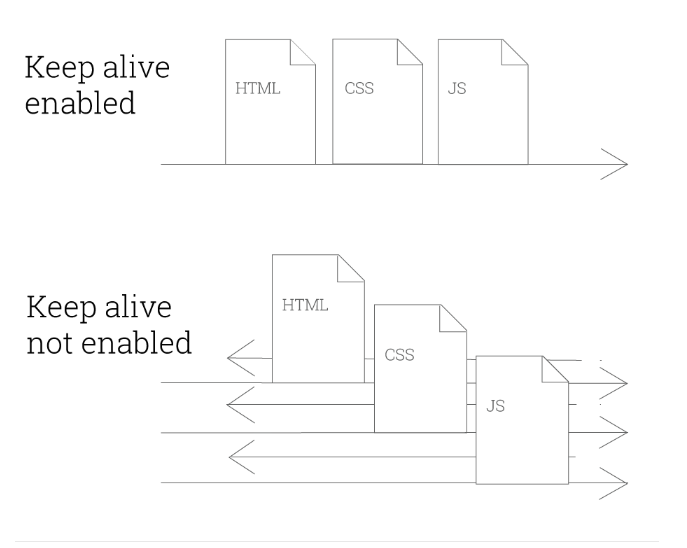
HTTP 1.1 부터는 keep-alive 기능을 지원한다. HTTP는 하나의 연결에 하나의 요청을 하는 것을 기준으로 설계가 됐다. 요즘 웹 서비스의 경우 간단한 페이지라고 해도 수십개의 데이터 - 이미지, 문서, css, javascript - 등이 있기 마련인데, HTTP의 원래 규격대로라면 웹페이지를 하나 표시하기 위해서 연결을 맺고 끝는 과정을 수십번을 반복해야 한다. 당연히 비효율적일 수 밖에 없다. 연결을 맺고 끝는 것은 TCP 통신 과정에서 가장 많은 비용이 소비되는 작업이기 때문이다. 예를들어 HTML로 표현된 문서를 다운로드 받는다고 가정해 보자. 이 문서에는 20여개 정도의 이미지, css, javascript 파일이 있다. Keep alive를 지원하지 않을 경우 다음과 같은 과정을 거친다.
- 웹 서버에 연결한다.
- HTML 문서를 다운로드 한다.
- 웹 서버 연결을 끊는다.
- HTML 문서의 image, css, javascript 링크들을 읽어서 다운로드해야할 경로를 저장한다.
- 웹 서버에 연결한다.
- 첫번째 이미지를 다운로드
- 연결을 끊는다.
- 웹 서버에 연결한다.
- 두번째 이미지를 다운로드
- 연결을 끊는다.
모든 링크를 다운로드 할 때까지 반복한다. Keep-alive 설정을 하면, 지정된 시간동안 연결을 끊지 않고 요청을 계속해서 보낼 수 있다.
- 웹 서버에 연결한다.
- HTML 문서를 다운로드 한다.
- Image, css, javascript 들을 다운로드 한다.
- 모든 문서를 다운로드 받았다면 연결을 끊는다.
Keep alive 설정
Keep-alive는 HTTP/1.1 부터 사용할 수 있다. 모든 웹서버와 브라우저는 HTTP/1.1을 지원한다고 가정해도 무방하다. 아래와 같은 과정을 거쳐서 keep alive를 설정을 한다. 웹 브라우저는 요청 헤더에 keep-alive 방식의 연결을 할 것을 명시한다. chrom웹 브라우저로 www.joinc.co.kr로의 연결 요청을 캡춰했다.
웹 서버의 설정이 kepp-alive 방식을 지원하도록 설정돼 있다면, 응답 헤더에 keep-alive 정보를 실어 보낸다. www.joinc.co.kr 서버의 응답 헤더의 일부분이다. connection:Keep-Alive : 연결을 keep-alive 상태로 유지한다. Keep-Alive:timeout=5, max=100 : 하나의 연결당 5초동안 유지한다. Keep-alive 연결은 최대 100개까지 허용한다. keep-alive는 하나의 연결로 여러 요청을 처리하기 때문에 효율적이긴 하지만, 연결이 그만큼 길어지기 때문에 동시간대 연결이 늘어난다. 운영체제에 있어서 연결은 “유한한 자원”이다. 연결을 다 써버리면, 서버는 더 이상 연결을 받을 수 없게 된다. Max 값을 이용해서 keep-alive 연결을 제한하는 이유다.
참고자료
http에 대한 설명
https://ko.wikipedia.org/wiki/HTTP
https://junjangsee.github.io/2019/07/29/network/network-01/
keep-alive와 요청 데이터 포멧, 응답 헤더 포멧…. 이정도면 출처이다. https://www.joinc.co.kr/w/Site/Network_Programing/AdvancedComm/HTTP
tcp/ip설명
출처: https://hahahoho5915.tistory.com/15 [넌 잘하고 있어]